
Recommendation systems learning to speak human
From Instagram's new algorithm to how platforms might finally explain what they think they know about us

A few months ago, I wrote about how recommendation systems seem to get increasingly confident about who I am and how it doesn’t necessarily end up giving me better recommendations.
The more they learn, the narrower they become.
You watch or engage with some content, and you’re shown more of it. Over time, your feeds become filled with the same creators, the same topics, and the same patterns. You’d expect it to work perfectly, as it’s doing what it’s designed to do. But we all end up finding ourselves drowning in the same content over and over.
Recently, Instagram announced a new feature called “Your Algorithm”, which lets users see and modify the topics Instagram thinks they’re interested in.
Reading Adam Mosseri’s thread about it, I realized we might be talking about the same phenomenon from different angles.

His argument is that recommendation systems have become increasingly one-sided. They observe what we click, watch, share, and save, but we have very few ways to tell them directly what we want.
For years, recommendation systems have relied almost entirely on behavior. Which makes sense. Don’t we, product people, love saying “Don’t do what users ask for, watch how they behave”?
Users click, the algorithm learns, they click something similar again because it’s there again, because it’s recommended, and the learning is reinforced. This doesn’t leave much space for new discoveries.
If you suddenly become interested in architecture, photography, or cooking, the algorithm has to figure that out indirectly. It waits for enough hints to appear before adjusting (although I feel like it’s been getting much faster lately).
Giving people a way to explicitly influence that process is a meaningful improvement. Instead of hoping the algorithm eventually notices a change, you can tell it.
But actually, the most interesting part for me was Mosseri’s explanation for why something like this is becoming technically feasible now.
We all know choosing interests isn’t new.
Platforms have been asking users to pick categories for years. You might remember picking them on Pinterest, Medium, or similar platforms. Countless products have done some version of it during onboarding.
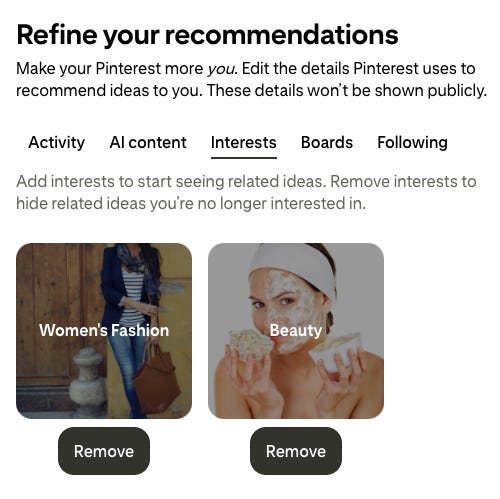
The difference is that those ones started with category tags that had to be defined by someone first.
They decided what buckets existed, and users picked from those buckets.
Modern recommendation systems don’t really work that way anymore. Or at least, it’s not that simple.
Under the hood, they’re not organizing content into neat categories like “Photography”, “Travel”, or “Design”. They’re organizing content into enormous mathematical spaces where similar things end up close together.
Mosseri gives a simple example of how a photo of one of Colman Domingo’s outfits might sit close to a video from his stylist about menswear, which sits close to the broader topic of men’s fashion.
Or think about how a video about building a home office might sit close to a desk setup review, which sits close to a productivity creator discussing focus, which sits close to content about remote work.
Algorithms today can understand these relationships. But more importantly, they are able to communicate them to you, instead of fitting them into the best available bucket.
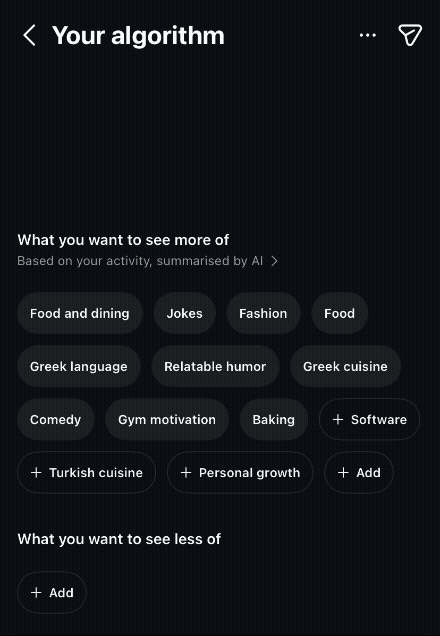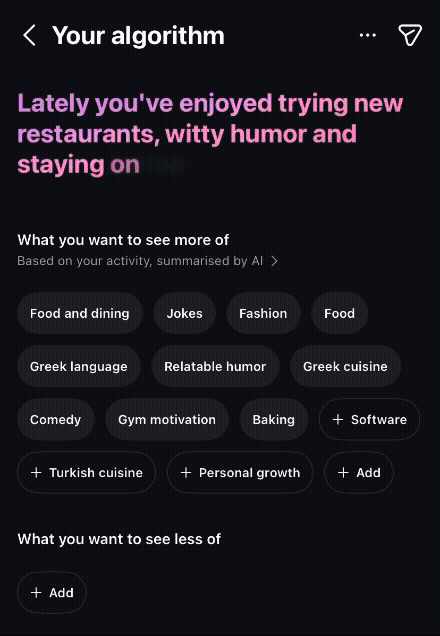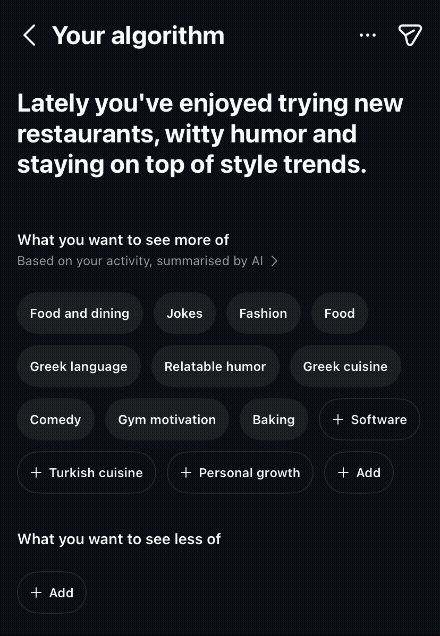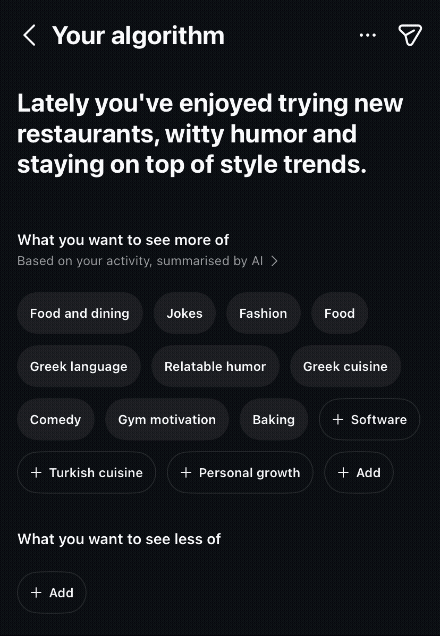
LLMs change this dynamic by translating what recommendation systems already know into language people can understand.
Instead of showing a cluster of coordinates in a vector space, they can potentially summarize those relationships as:
“You seem interested in men’s fashion.”
Or take it even further:
“You seem to enjoy creators who explain complex topics through storytelling.”
“You often engage with content about craftsmanship, especially cooking and woodworking.”
Being able to edit those sounds simple, but it’s actually a pretty significant shift and is different from selecting categories during onboarding.
One is declaring interests before the platform knows anything about you, and the other is reacting to a model that has already spent months or years observing your behavior.
It’s less like filling out a profile, more like reviewing and challenging somebody else’s assumptions about you.
Now with all these new changes, it makes me wonder, if LLMs become the interface to recommendation systems, what else becomes challengeable?
We’re starting to get a chance to edit our content tastes, but maybe tomorrow it’ll be more complex than this.
Imagine sitting in front of your TV on a lazy Friday evening, and instead of just scrolling through countless options until you give up, you just tell it:
“I’m in the mood for something lighter than usual.”
Or imagine instead of getting recommendations based on genres because “you watched” something in the same category, you can explain why you actually liked it, and maybe it was more than its genre:
“I really enjoyed La Passion de Dodin Bouffant, but it’s not because it was cooking-related or French. I like a complex romance set in the late 1800s. What else have you got?”
Knowing what we like is one thing. Understanding why we like it is another. Sometimes, I wonder whether there are patterns in our preferences that we can’t even articulate ourselves, but neural networks eventually might.
I’d be curious to see where that leads.
Well written, Ipek! Part of me is also concerned about how we're getting "trained" not to do discovery the way we used to. Twenty years ago, if you wanted to kill time with TV, you'd switch it on, scroll, and genuinely go through the "discovery": sports, music, drama, NatGeo, whatever. Now we're trained not to do that, or we have to work hard to do the discovery ourselves. It goes both ways, I guess: how the AI is trained for humans, and how humans get trained by the product..."
Great read. With the recommendations getting more tailored, I am concerned about not only the content’s topic, but about the angle I am shown often: things that validate my opinions rather than challenging them